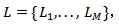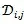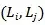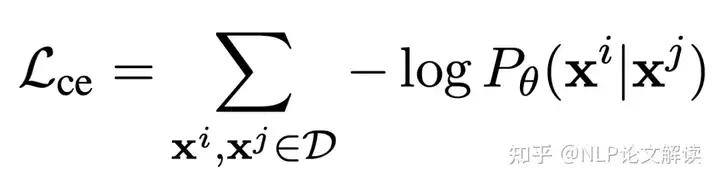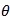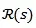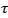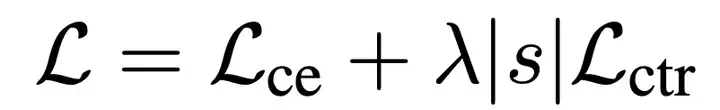+ r9 ^7 `1 ]" B; t ©原创作者 | 朱林
+ e. {% W6 u, S" R( U% u
论文解读:
6 x4 `# D3 e- l) }
Contrastive Learning for Many-to-many Multilingual Neural Machine Translation
/ K+ |/ |& I6 V$ F0 l) n
论文作者:
# ~: w, P# F6 C5 D& ^6 [5 B
Xiao Pan, Mingxuan Wang, Liwei Wu, Lei Li
+ i0 y# \7 ~8 Q 论文地址:
6 T" W( H! P, ?; G https://aclanthology.org/2021.acl-long.21.pdf
0 E: q* Z' Y y) C! N 收录会议:
7 f) o: X7 a8 Y8 x% @4 L2 S$ W5 j
ACL2021
' R6 Y$ \ B8 t) _ @ x 01 介绍
5 J9 f- x% C+ j. W7 D
目前机器翻译的研究热点仍然集中在英语与其他语言翻译的方向上,而非英语方向的研究成果仍然寥寥无几。
6 S! d* X' I) T: O 如何有效利用不同语言的特征去构建模型,提高多种语言,尤其是非英语之间的翻译水平是个越发重要的课题。
- L' e" x, ?( ~% H4 k& H7 ` 传统思路中,为了解决两种语言机器翻译问题,人们往往分别学习这两种语言的特征再匹配,而忽略了两种语言在特征表达上的较大差异,导致模型效果较差。
8 j5 @- Q+ b$ q% L 本篇ACL会议论文提出了一种统一多语言翻译模型mRASP2来改进翻译性能,利用多语言对比学习能综合表达的优点改进了机器翻译性能,尤其提高了非英语方向的翻译质量。
0 B3 x7 \6 ^5 H* q+ E9 R 该模型由两种技术支撑:
0 Z6 o2 N4 B9 B) t$ R1 J' F: r
(1)对比学习,用于缩小不同语言表示之间的差距;
4 |5 h! N. b2 Z (2)对多个平行语料和单语语料进行数据增强,以进一步对齐标记表示。
; v1 j# e) |0 C% e
实验表明,以英语为中心的方向,mRASP2模型的性能优于现有的最佳统一模型,并且在WMT数据集的数十个翻译方向上的性能超过了当前性能顶尖的mBART模型。
8 S' D; G% y) P/ [& ^ 在非英语方向,与Transformer基线模型相比,mRASP2也实现了平均10 BLEU(性能指标)以上的性能改进。
9 x! Q; {/ X) Q+ ? J
02 方法
6 T3 G+ O) N7 Q, ~$ w
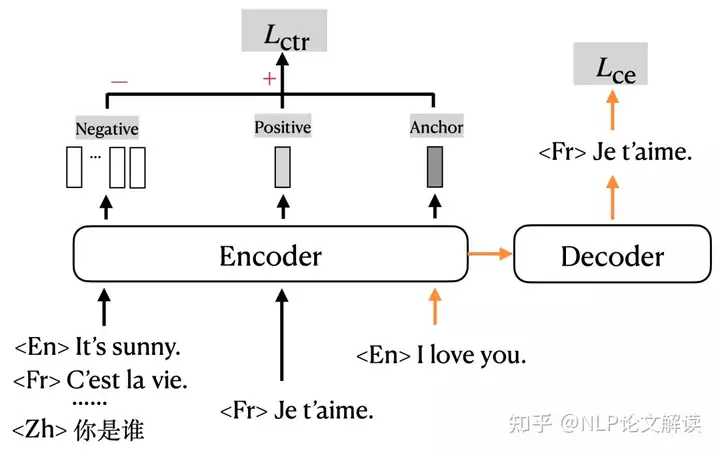
mRASP2需要输入一对平行句子(或增强伪平行句子),并使用多语言编解码器计算交叉熵损失。此外,它计算正样本和随机生成的负样本的对比损失,总体框架如图1所示:
- k0 T2 }* G- ^5 C4 ^3 U/ G: [ 图1 mRASP2模型图2 通过替换同义词词典中具有相同含义的单词,对平行数据和单语数据进行对齐增强。生成包括伪平行示例(左)和伪自平行示例(右)。多语言转换器
( r6 `. p! t3 z8 I& V: T! s9 v' h
模型采用了多语言神经机器翻译(Neural Machine Translation, NMT)模型学习多对多映射函数f,以将一种语言翻译成另一种语言。
( V! V# T% @; g/ ~
为了区分不同的语言,作者在每个句子之前添加了一个额外的语言识别标记,用于源端和目标端。
( y' | U5 U3 W. e; n3 m3 B mRASP2的基础架构采用的是最先进的Transformer模型。与之前的相关工作略有不同,作者选择了12层编码器和12层解码器,更多的层数可以增加模型的容量。
- @6 H0 d0 |1 ^3 c2 P 为了简化深度模型的训练,作者对编码器和解码器的Word Embedding和Pre-norm Residual Connection应用Layer Normalization。
9 p9 ]" ]% y" y3 Z
因此,作者的多语言NMT比Transformer模型强得多。
# K1 j7 Q: X! q2 a( S 作者定义了
; H2 F' [& L" i
' M+ Z8 |* I1 @# M. H4 [$ B
其中L是涉及训练阶段的M种语言的集合。
$ K& P! v6 p) ~( G1 B. X 8 [( D( z2 r* G7 t
表示
# F; Z8 T' E1 l/ |. h# G: K
& s: W3 I& f' `* S
的平行数据集,
- [& ]. m) K0 O" K* S6 O' y. X D表示所有平行数据集。该模型训练的损失函数采用了交叉熵的形式,定义为:
m: |2 c+ r# y4 R( m
( W$ j7 ^ B% c A
7 N% Z& S+ L C$ n
其中
& {/ O0 x( B6 o2 j( e / Q2 P* m1 S' L
语言中的一个句子,
L1 M( @1 J! `" B# p, S- P# L
1 D6 j" N0 q4 G2 ^/ v: i# r' d 是多语言Transformer模型的参数。
: i- n u* n- ?. u3 T1 {, v& w' ] 多语言对比学习
9 p% l" Z8 q2 H! r* D 模型采用了多语言转换器来隐式地学习不同语言的共享表示。mRASP2引入了对比损失来明确地将不同的语言映射到共享的语义空间。
* [) c8 {# I( {) s) m 对比学习的关键思想是最小化相似句子的表示差距,最大化不相关句子的表示差距。
1 Z! ?6 J% @9 v* S2 H+ y 形式上,给定一个双语翻译对
9 q5 ^+ u& K! I. o( J) g
+ h4 X2 ?: }+ p1 r" q3 e1 K9 x 对比学习的目标是最小化以下损失:
+ O. T: W8 H: e1 e- P" N" E* M9 l' ]0 e
* @; I, P) N; w& \- s- H$ K& z3 p ' F" z6 }3 E# ?0 n
其中sim(.)计算不同句子的相似度。+和-分别表示正样本还是负样本。
' u8 a3 W6 ^/ Z9 |' M# p. z$ \
: w7 q, Z4 e4 l4 n3 [* S) X 表示任意句子s的平均池化编码输出。
* y7 Y2 Q6 e8 D& M2 L. e( { 9 n0 R( l+ K7 A
控制着区分正样本和负样本的难度。
7 W0 X2 p% W' \( r 在mRASP2的训练过程中,可以通过联合最小化对比训练损失和翻译损失来优化模型:
. c1 \/ ^- e6 T7 J' U! E5 X
& ^# x& f7 n' j' R 其中λ是平衡两个训练损失的系数。
, u& A9 n3 O, h4 s% Q7 {' x
4 O @# L! W' K8 f4 S# Y 对齐增强
! J* l$ ]% F! X+ s 作者基于前人提出的随机对齐替换(Random Aligned Substitution, RAS)技术——一种为多语言预训练构建代码切换句
0 ?$ X. y$ H7 T$ s! K: ~3 r! R
9 C1 O; P- ]% W+ |0 D. c: ?
$ j O" @: Z r5 {! m# L 03 实验
! @2 F% E) Q/ b* p. i4 O/ O 以英语为中心的方向
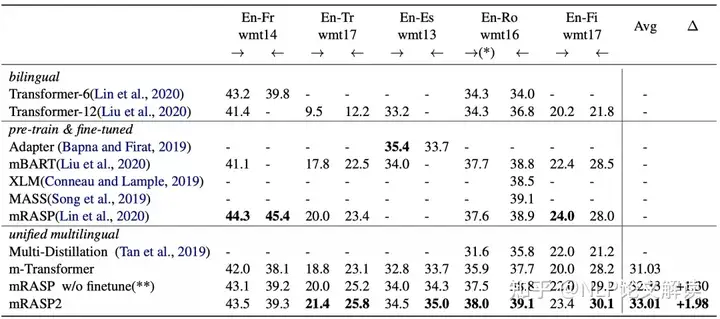
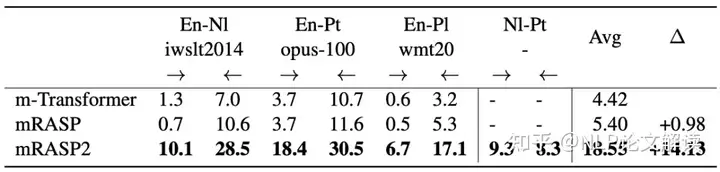
) S& w9 Y0 @2 c% g 表1和表2中罗列了作者实验中得到的具有代表性的多个翻译方向的性能增益结果。
. M! V! Q( B$ |- v+ d 表1 监督翻译方向上的性能对比。图2 attention score 和attribution score 示意图监督翻译如表1所示,mRASP2在10个翻译方向上显著提高了多语言机器翻译的基线。以前,多语言机器翻译在资料丰富的场景中表现不佳。
6 j4 c- I/ \2 H- ^9 u; R c 作者总结了其成功训练的关键因素包括:
6 j J; C H9 m& S0 P& [ (1)提高了训练批次:每批包含大约300万个词;
+ {2 E& | n* E" b$ h
(2)增大了模型层数:从6层扩大到了12层;
( j4 X9 U; m+ |; |. l
(3)使用正则化方法来稳定训练。
, Y: M- R- ^" a
无监督方向如表2所示,作者观察到mRASP2在无监督翻译方向上取得了明显有效的结果。实验中,m-Transformer模型永远不会观察到En-Nl、En-Pt和En-Pl的语言对,即它在En→X的翻译方向上完全无效。相比之下,mRASP2平均获得+14.13BLEU分数,而没有明确引入这些方向的监督信息。
! q0 o6 X4 j9 ]+ b' n4 Y
此外,mRASP2在Nl↔Pt方向上获得了明显有效的BLEU分数,即使它只在双方的单语数据上进行了训练。这表明通过在统一框架中简单地将单语数据与平行数据合并,mRASP2就可以成功地实现了无监督翻译。
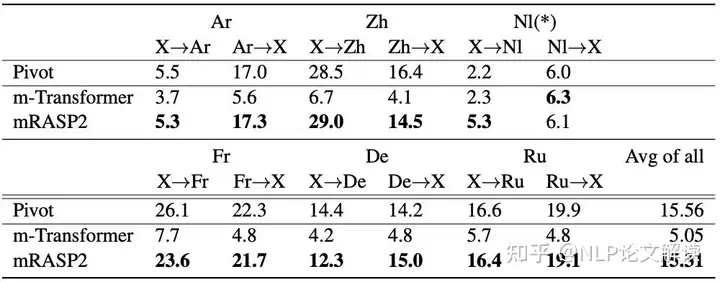
9 B7 h5 m2 n) b 非英语方向的零样本翻译
6 V3 m& G" d7 }& A/ p4 d6 j
表3 零样本翻译性能对比零样本翻译一直是多语言神经机器翻译中的一个有趣话题。以前的工作表明,多语言NMT模型可以直接进行零样本翻译。
' D, X4 G9 i( {# h6 w! Y 作者在OPUS-100零样本测试集上评估了mRASP2。作者发现mRASP2性能显著优于m-Transformer,并且大大缩小了与基于Pivot的模型的差距。这符合作者的直觉,即弥合不同语言的表示差距可以改善零样本翻译。
, n2 P) V5 @, b7 k: B 作者认为主要原因是对比损失、对齐增强和额外的单语数据能够更好地表示与语言无关的句子。值得注意的是,其他模型是以牺牲英语为中心方向上翻译质量作为代价实现了零样本翻译的性能提升。
5 P5 D0 f1 L& A 相比之下,mRASP2在不损失以英语为中心的方向上的性能的情况下,大大提高了零样本翻译的性能。因此,mRASP2具有服务于多对多翻译的巨大潜力,包括以英语为中心和非英语方向。
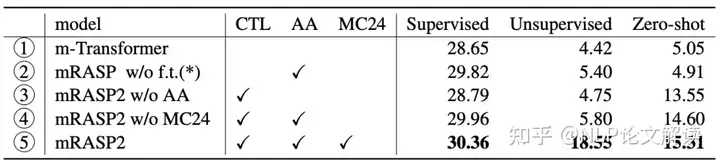
6 v- l: @2 M2 k, D, p! ] F 消融实验
$ o* {3 J7 b- q) f! S7 E8 e
表4 mRASP2在不同设置下在不同场景中的平均BLEU汇总为了更好地解释mRASP2的有效性,作者评估了不同设置模型的性能。作者总结了表4中的实验结果。
3 p/ w" n- f7 v. G2 k
①对③:③在有监督和无监督的场景中的性能与m-Transformer相当,而在零样本翻译方面实现了显著的BLEU改进。这表明通过引入对比损失,作者可以在不损害其他方向的情况下提高零样本翻译质量。
" _9 F: C$ z$ k4 H
②对④:②在零样本方向上表现不佳。这意味着对比损失对于零样本方向的性能至关重要。
! m' w; A6 Q5 Y5 A$ b! ~* [# s ⑤:mRASP2在所有三个场景中都进一步改进了BLEU,尤其是在无监督方向上。
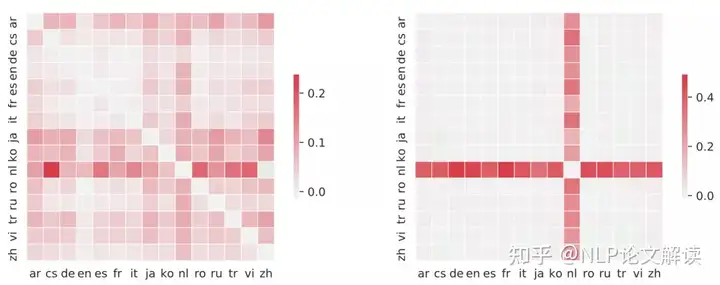
: O" s. m2 k1 r: F: | 相似性搜索
) x) W7 {& S* Z8 ^
图3 精度改进图,更深的红色意味着更大的改进。mRASP2 w/o AA模型与m-Transformer模型的精度差(左),mRASP2模型与mRASP2 w/o AA模型的精度差(右)如图3所示,为了验证mRASP2是否学习了更好的表示空间,作者进行了一组相似性搜索实验。相似度搜索是根据余弦相似度寻找另一种语言中每个句子的最近邻的任务。
2 h3 u0 V+ P: ~5 c
作者使用相似性搜索任务的准确性作为跨语言表示对齐的定量指标,并用实验证明了mRASP2更有利于这项任务,因为它拟合了跨语言的表示差距。
8 l" R6 S' J( ~: P4 W' h U3 r 可视化
, a. Q% p; ~) m" z8 k- L3 s' q- u9 H
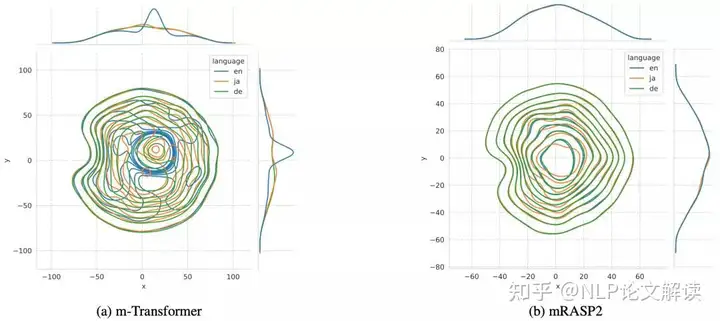
图4 使用T-SNE降维到2维后表示的双变量核密度估计图。蓝线是英文,橙线是日文,绿线是德文。为了可视化跨语言的句子表示,作者在Ted-M中检索每个句子的句子表示,在高维空间中产生34260个样本。
) G4 G$ `0 H D( H1 J( x& P 为了便于可视化,作者应用T-SNE降维方法将1024维降到2维。然后作者选择3种代表性语言:英语、德语、日语,并基于2维表示描述双变量核密度估计。
- z3 L; p. Q* e0 @ 在图4中明显可以看到,m-Transformer无法对齐3种语言。相比之下,mRASP2更接近地绘制了3种语言的表示。
" W: Z/ [; O5 {- T' u# n7 k
04 结论
8 z+ ~; k7 z( x# b7 m2 S% e0 R
本篇论文中,作者证明了对比学习可以显著改善零样本机器翻译性能。结合额外的无监督单语数据,作者在多语NMT的所有翻译方向上均取得了实质性的改进。
/ p* R! ^+ n2 j 通过分析和可视化mRASP2,发现对比学习倾向于缩小不同语言的表示差距。
! O: w* }( e; y% F" [3 J0 t3 X
作者的结果还表明了训练出真正的多对多多语言NMT的可能性,该NMT在任何翻译方向上都能很好地工作。
$ L3 Z3 F- M+ b+ g. `* x
通过对本篇论文的解读,我们能够发现机器翻译正在向多个不同的研究方向继续深入发展:
. A4 W [) C+ t! y (1) 英语方向翻译正在朝非英语方向进行横向扩展和迁移学习;
# _6 ~7 {8 D! ^+ c5 J* |' m (2) 语言特征表达正在朝更多维度和更有解释性的维度进行扩展,比如本文的多语言融合特征缩小了语言表达差距并进行了可视化。
7 l7 X8 T. q) o C! R* |; g
(3) 多语言统一翻译模型的构建成为趋势。
3 g+ E$ ~% R+ d, S8 d P& [9 X 注:本篇论文的代码、数据和训练模型均可从Github上获得:
# b D+ q" N9 ~' I/ Y https://github.com/PANXiao1994/mRASP2
% k+ _/ U9 @- U
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。
- B, g, ?$ h! D y' Y